Какие способы выгрузки из 1С в Greenplum существуют
-
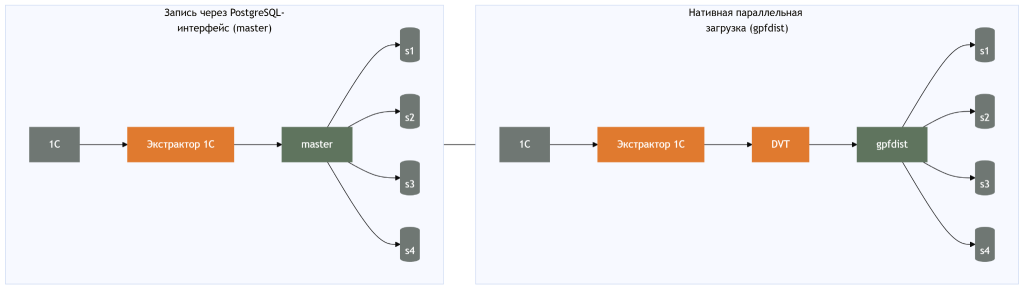
Запись через PostgreSQL-интерфейс (через master-узел).
-
Нативная параллельная загрузка через gpfdist.
Это не просто разные инструменты — это разные модели взаимодействия с распределённой архитектурой Greenplum.
Запись через PostgreSQL: стандартная схема через master
1С → PostgreSQL-драйвер → master → сегменты Greenplum
Master — это точка входа в кластер. Через него проходят соединения и транзакции. После приёма данных master распределяет строки по сегментам в соответствии с ключом дистрибуции.
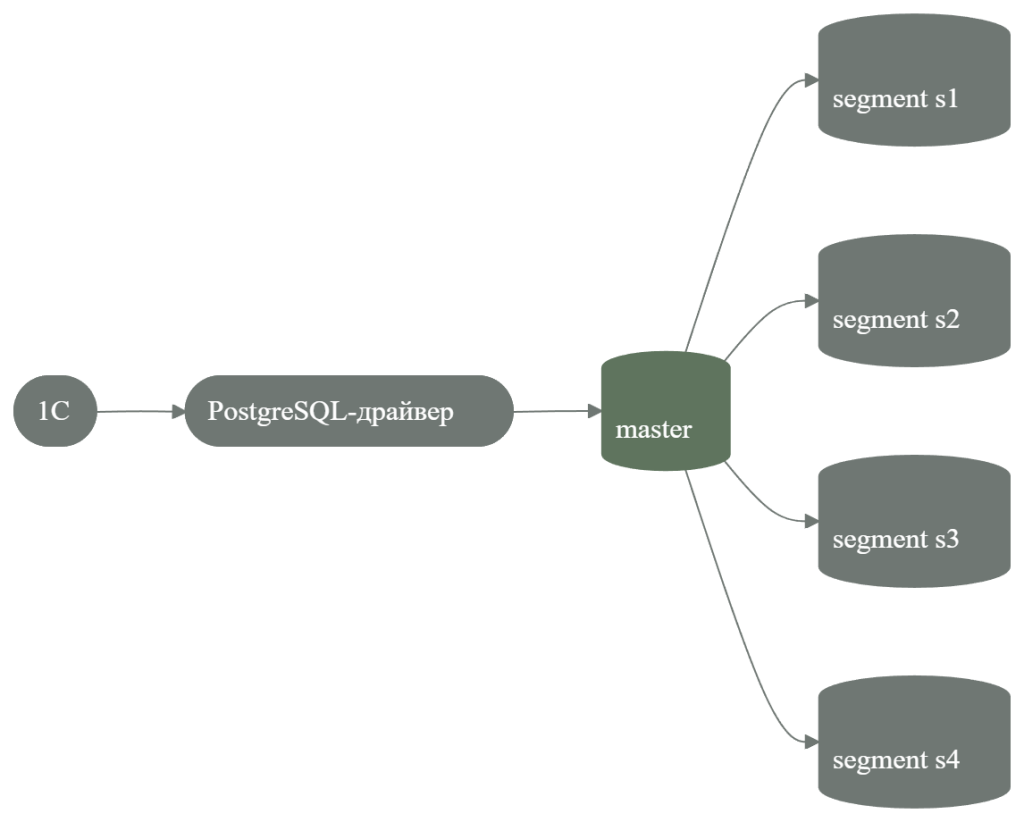
В чём архитектурное ограничение
При такой модели запись начинается с одной входной точки.
Даже если в кластере восемь или шестнадцать сегментов, поток данных сначала проходит через master. Он распределяет записи дальше, но вход остаётся один.
Это означает:
-
пропускная способность ограничена входной точкой,
-
при росте объёма master может становиться узким местом,
-
запись масштабируется хуже, чем чтение.
При умеренных объёмах это работает стабильно и предсказуемо.
Проблемы начинаются при росте нагрузки.
Два типа параллельности: их важно не путать
В фактической архитектуре есть два разных уровня параллельности.
1. Параллельность на уровне извлечения и передачи данных
Её реализует Экстрактор 1С:
-
инкрементальная модель (CDC),
-
многопоточная выгрузка,
-
параллельная запись в таблицы,
-
последующее объединение.
Этот механизм универсальный. Он одинаково работает с PostgreSQL, MSSQL, ClickHouse и другими СУБД.
Но это не нативная сегментная параллельность Greenplum.
Параллельность реализуется на стороне передачи данных, а не на уровне сегментов кластера.
2. Параллельность на уровне сегментов Greenplum
Это нативная модель работы Greenplum.
Каждый сегмент может получать данные напрямую и выполнять запись независимо от других.
Именно эта модель обеспечивает линейное масштабирование записи.
Разница принципиальная:
-
в первом случае параллельность — на стороне источника и передачи;
-
во втором — на стороне распределённой СУБД.
Когда записи через master достаточно
Запись через PostgreSQL-интерфейс оправдана, если:
-
требуется регулярная инкрементальная загрузка,
-
объёмы умеренные,
-
нет жёстких требований к скорости full-load,
-
проект находится на этапе запуска.
Во многих проектах DWH именно с этого механизма и начинается.
Нативная массовая загрузка через gpfdist
Greenplum поддерживает собственный механизм массовой загрузки — gpfdist.
Модель работы выглядит иначе:
-
Формируются файлы с данными.
-
Файлы передаются в gpfdist.
-
Сегменты Greenplum считывают данные напрямую.
-
Загрузка выполняется параллельно.
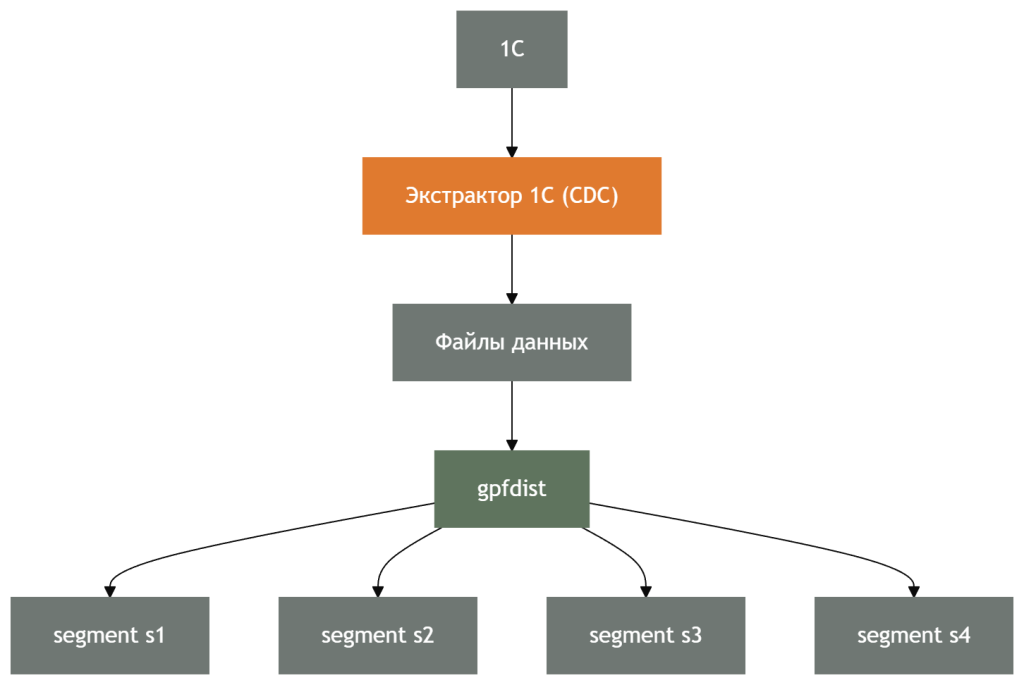
В этой архитектуре:
-
master не является точкой ограничения,
-
сегменты получают данные напрямую,
-
скорость записи масштабируется вместе с количеством сегментов.
Этот механизм используется для:
-
исторической инициализации,
-
крупных batch-загрузок,
-
высоконагруженных контуров.
Почему 1С не может напрямую работать с gpfdist
Платформа 1С не поддерживает работу с gpfdist напрямую.
Причина архитектурная: gpfdist — отдельный файловый сервер, требующий формирования файлов и управления процессом загрузки. Стандартная запись из 1С осуществляется через PostgreSQL-интерфейс и master.
Для использования нативной модели требуется отдельный ETL-контур.
Когда вообще нужен Greenplum
До определённого масштаба аналитические задачи можно решать на других СУБД, например ClickHouse.
Но когда объём данных растёт и требуется:
-
хранение больших исторических слоёв,
-
параллельная обработка массивов,
-
сложные трансформации,
-
масштабирование вычислений,
распределённая архитектура становится необходимой.
Greenplum используется там, где критична масштабируемость хранения и обработки.
Это инструмент для определённого класса задач, а не универсальная замена любой СУБД.
Типовой промышленный сценарий: Greenplum + ClickHouse
В зрелой архитектуре Greenplum часто выполняет роль:
-
слоя хранения больших объёмов,
-
зоны переработки,
-
промежуточного хранилища.
После трансформации данные могут передаваться:
-
в витрины,
-
в ClickHouse,
-
в BI-платформы.
Один из типовых сценариев выглядит так:
1С
→ Экстрактор 1С (инкрементальная выгрузка)
→ Greenplum (Raw + переработка)
→ витрины в ClickHouse
→ BI

В такой модели:
-
Greenplum отвечает за масштабируемое хранение и переработку,
-
ClickHouse — за быстрые витрины и работу BI,
-
слои чётко разделены по задачам.
Промышленная реализация через ETL-контур
Если требуется использовать нативную параллельную загрузку Greenplum, необходим отдельный ETL-слой.
В экосистеме Denvic эту роль выполняет DVT (Denvic Visual Transformer):
-
работает на Python,
-
формирует файлы для массовой загрузки,
-
управляет пайплайнами,
-
оркестрирует процессы,
-
обеспечивает централизованный мониторинг.
Типовая архитектура:
1С
→ Экстрактор 1С (CDC)
→ Greenplum (Raw)
→ DVT (трансформация и массовая загрузка)
→ витрины
→ BI
![]()
Что учитывать при проектировании
При выборе механизма загрузки важно оценить:
-
объём данных,
-
частоту загрузки,
-
требования к SLA,
-
перспективу масштабирования,
-
нагрузку на 1С.
Если задача — регулярная синхронизация изменений, записи через PostgreSQL достаточно.
Если проектируется промышленный DWH с большими объёмами и историческими загрузками, потребуется ETL-контур и нативные механизмы Greenplum.






